





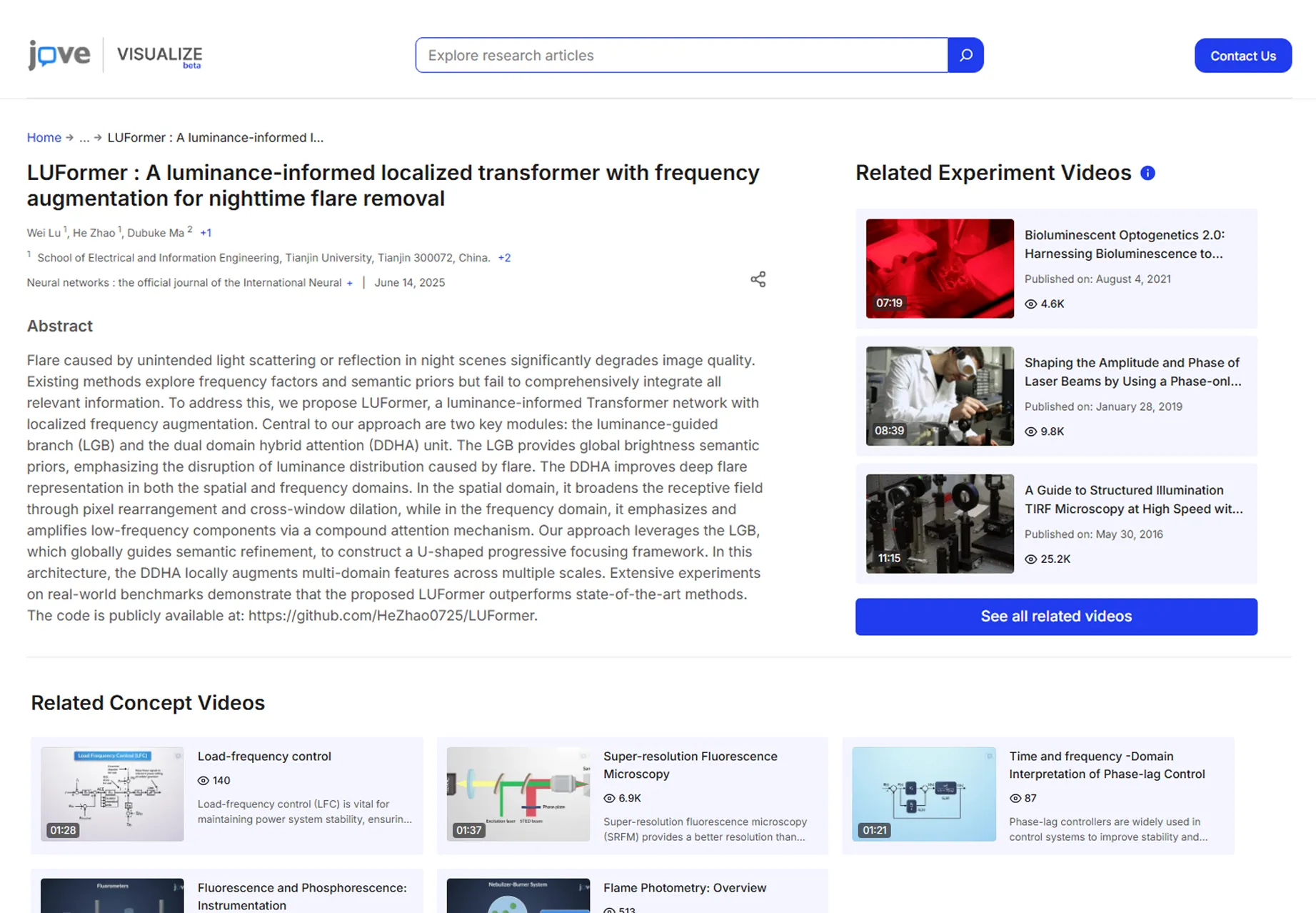
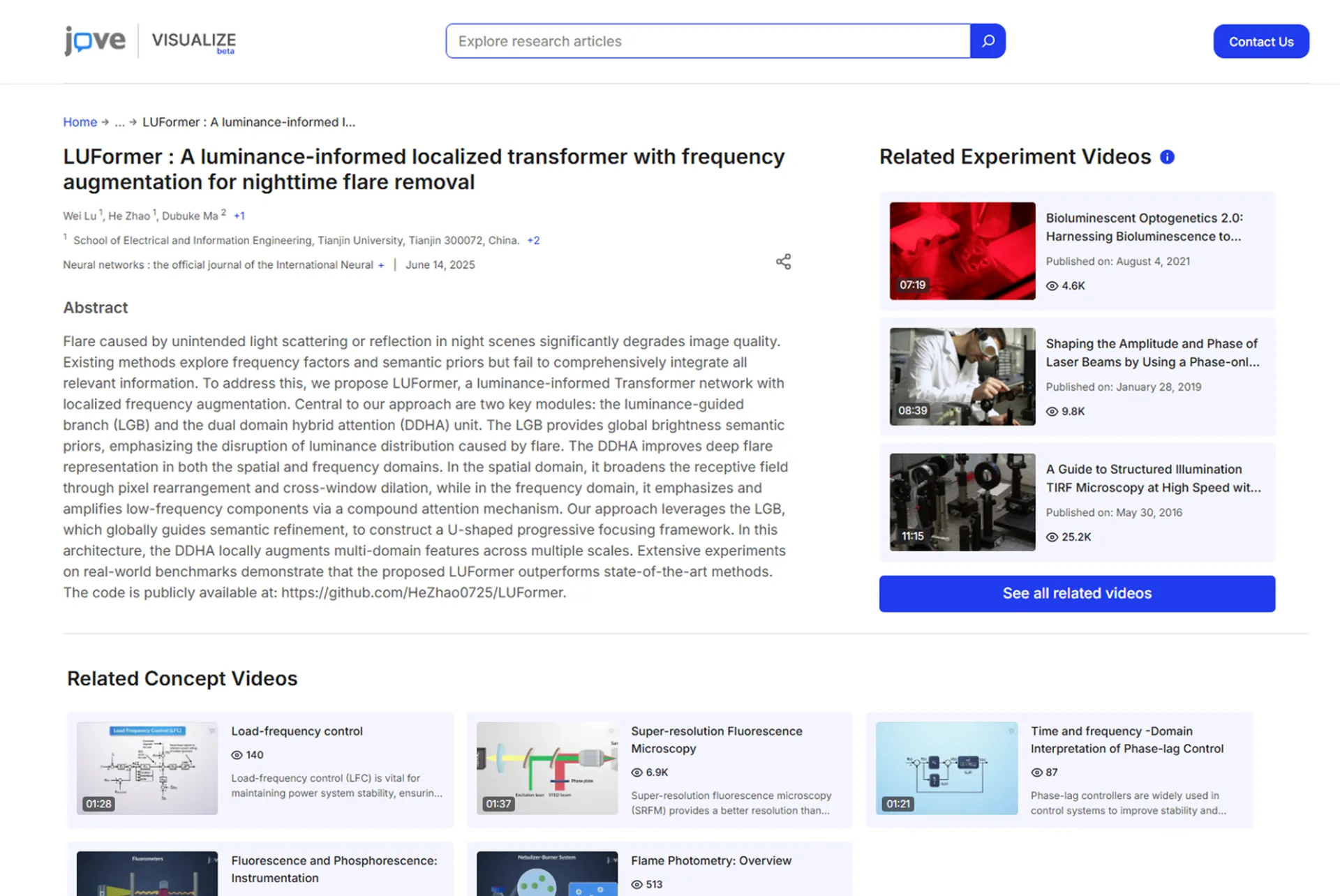
About the Project
JoVE (Journal of Visualized Experiments) is a leading provider of scientific video content for universities, laboratories, and research institutions worldwide. There are thousands of videos accessed across geographies and research areas. JoVE needed more than raw logs and reports. The requirement was to create a single, resilient data platform. This could log how its content was being discovered, watched, and cited.
Not just that, but the platform needed to be much intelligent. Enough to understand research patterns and sufficient for any researcher to search. So, the challenge wasn’t just building another analytics tool. It was to make those billions of access events, metadata updates, and engagement signals into clear, uniform data.
Our role was to turn an overburdened, API-heavy system into a fast, reliable, and future-proof analytics layer. This was done by rebuilding the service around Python FastAPI, OpenSearch, and a Docker architecture. We also collaborated with JoVE’s internal teams and partners to query, explore, and visualize content performance. All this had to be done without wrestling with slow dashboards or stale data.
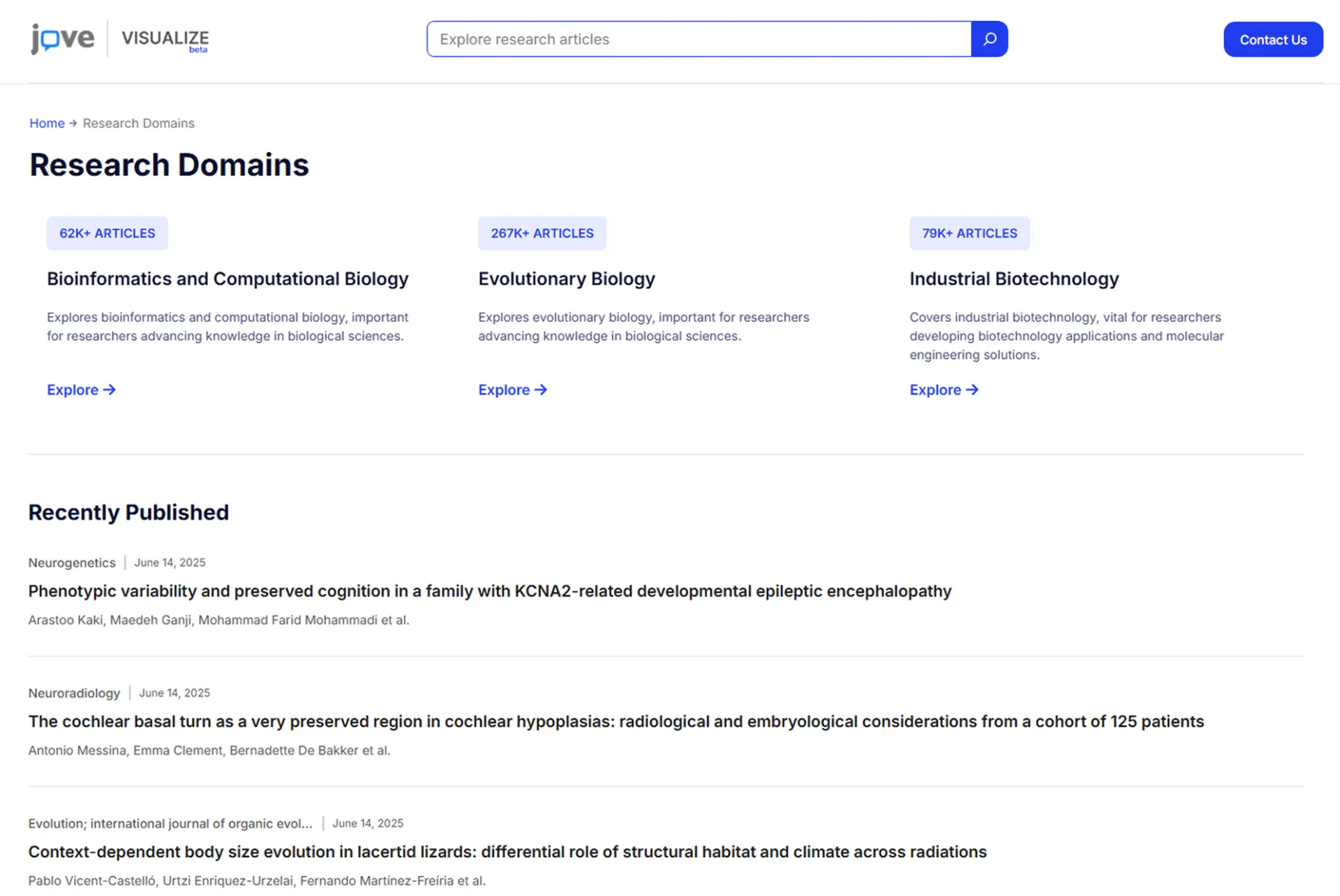
Key Project Deliverables
These were the specific project outputs, results, and progress expected at the end of each development phase.

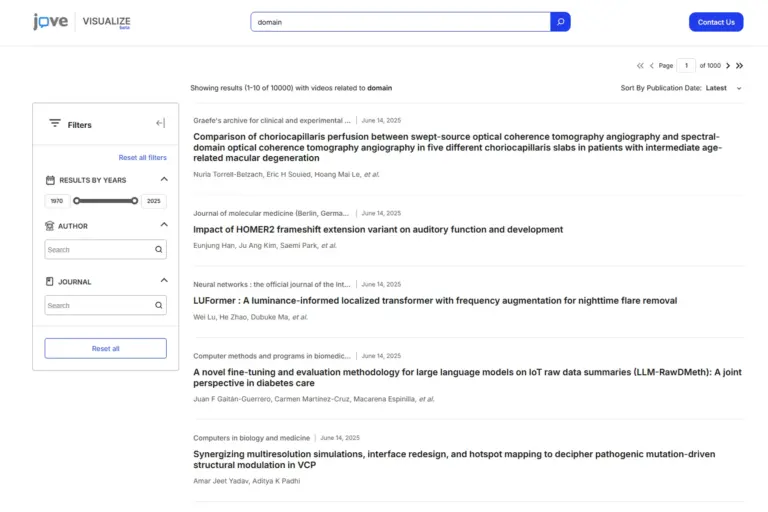
Real-Time Analytics
Deployed a quick analytics system that tracks content engagement. That too across thousands of institutions in real-time, for instant results of research trends and usage.

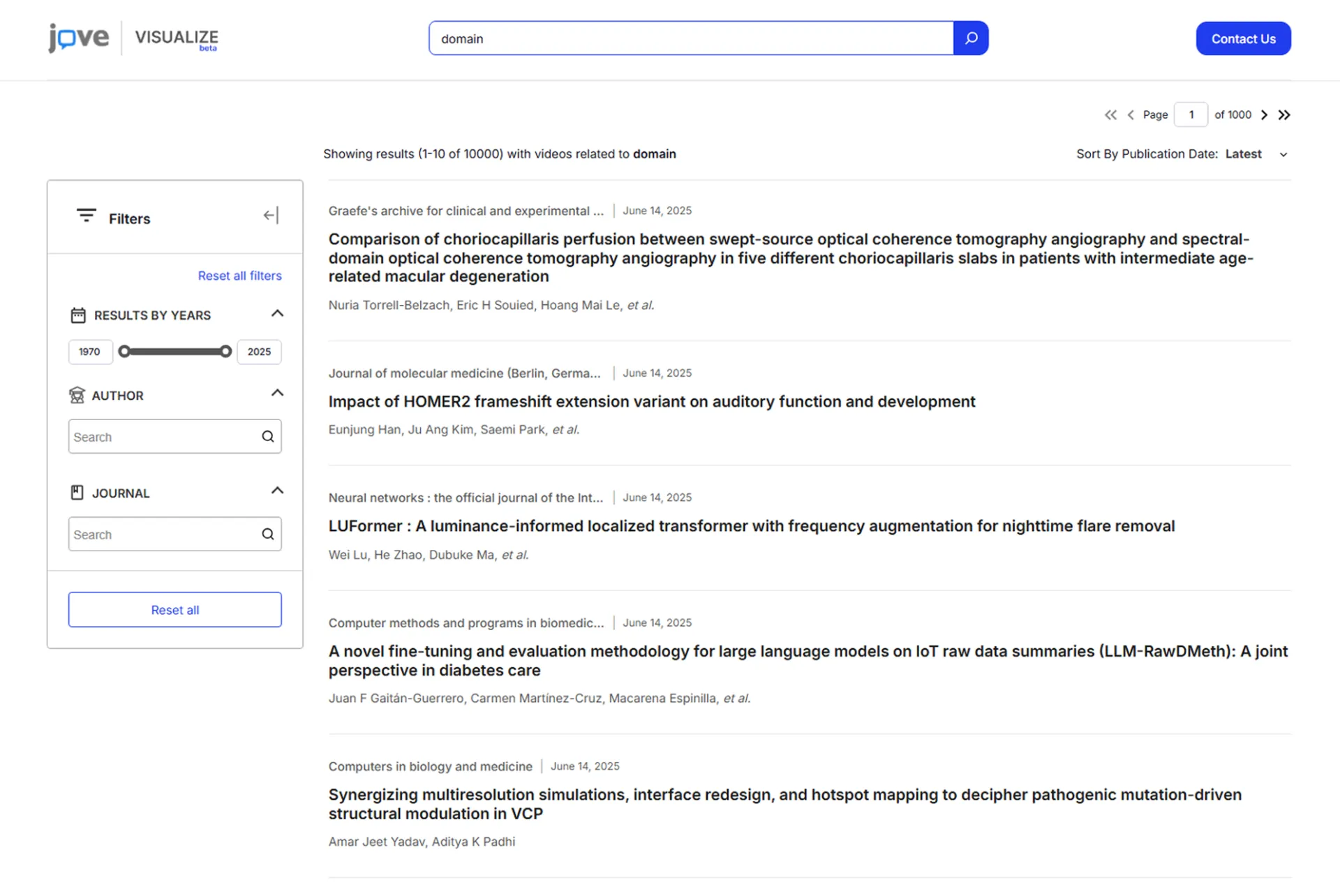
Advanced Search & Filtering
Built search infrastructure capable of processing complex queries across billions of access logs. This turned raw data into meaningful institutional pointers in seconds.

FastAPI Performance
Developed a modular FastAPI optimized for hasty scenarios. This helped in easy integration with dashboards and third-party research tools with fast response times.

Automated Data Fetching
Engineered a reliable data ingestion system that automatically processes and indexes incoming metrics. This kept the system current without manual intervention.

OpenSearch Integration
A simple integration to solve search issues from the backend. High-performance search and aggregation across billions of usage and metadata records.

Docker-based Deployment
We containerized services and configurations. For predictable deployments across staging and production environments, it was necessary and a wise decision.
Major Project Challenges
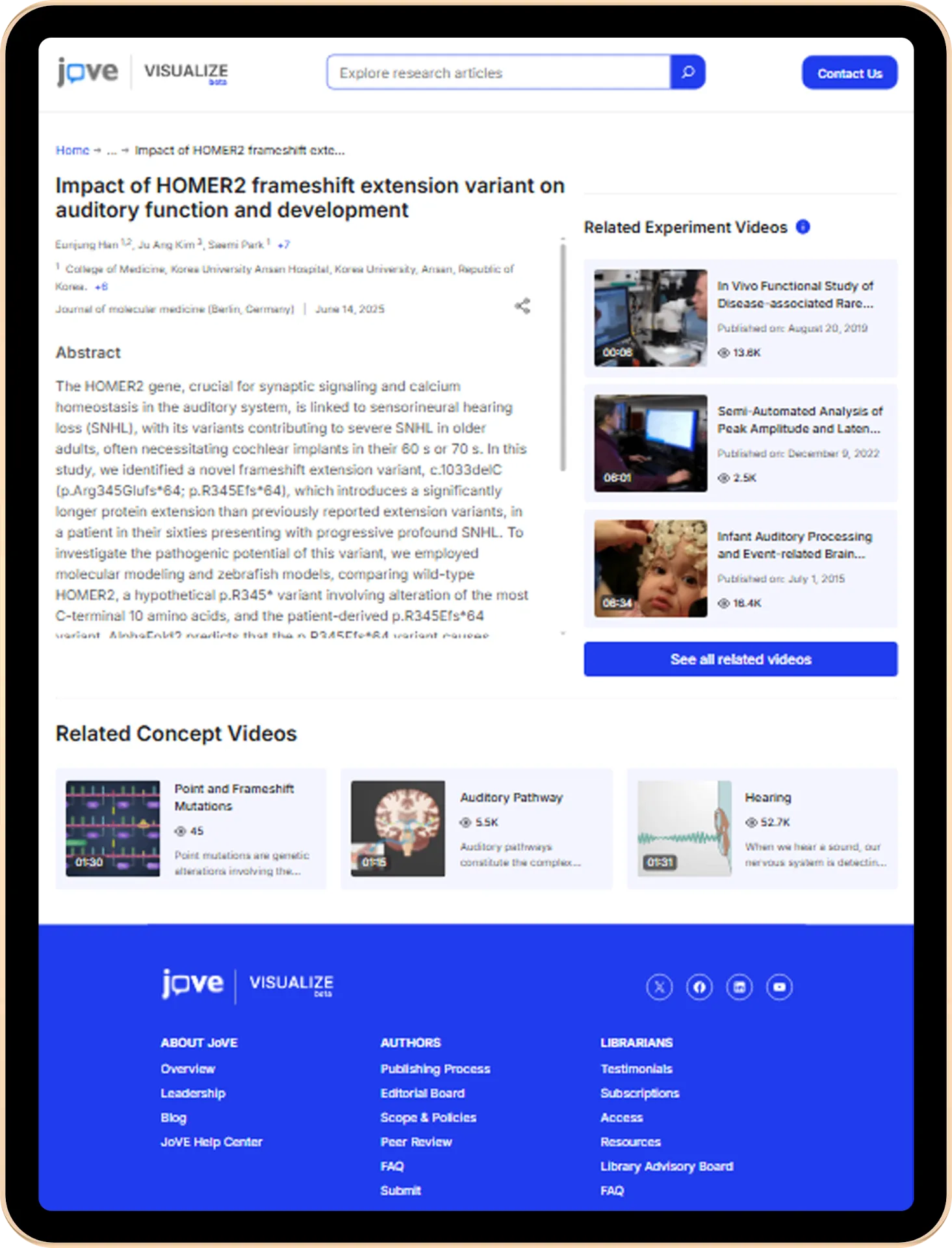
When JoVE Visualize first launched, it seemed like a solid solution. But as the platform gained adoption across hundreds of institutions. This resulted in an increase in volume of usage data, and the system’s limitations became painful.
Researchers couldn’t run complex queries without the system choking. Dashboard loads took a long time as well. Also, there was no real-time reporting. Basically, the infrastructure wasn’t built for the scale it was now expected to handle.
Another major problem was that they had outgrown their database architecture. MySQL’s search capabilities couldn’t handle the billions of records they were processing. Updating metadata across these billions of records took hours instead of minutes.
This wasn’t a minor performance issue. This was limiting how their users could extract value from their own data. Researchers couldn’t ask the complex questions that actually mattered to their work.
Overall, JoVE needed a platform that could behave like its user base. Global, always-on, and ready to serve complex questions about how scientific content performs in the real world.
Solutions & Impact
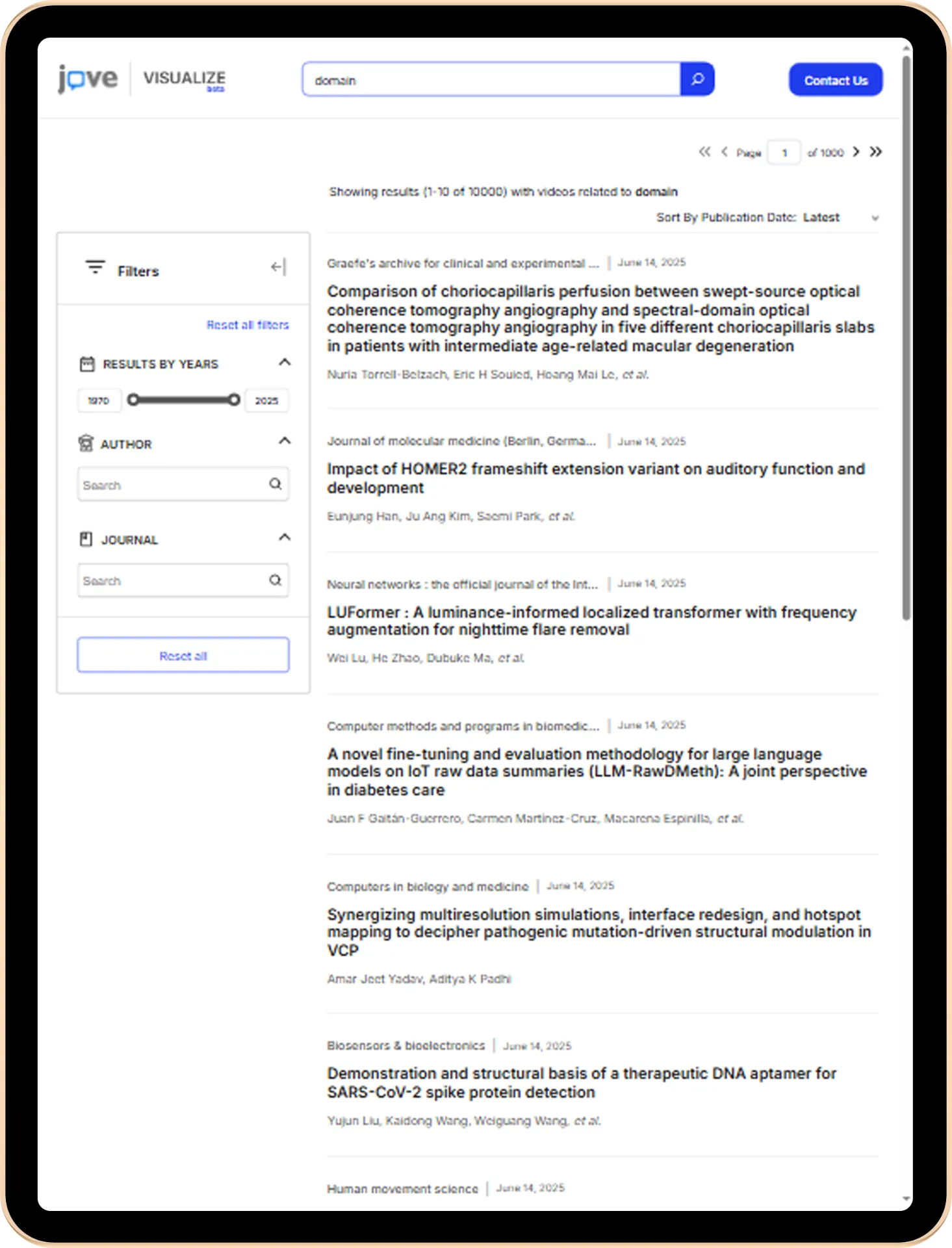
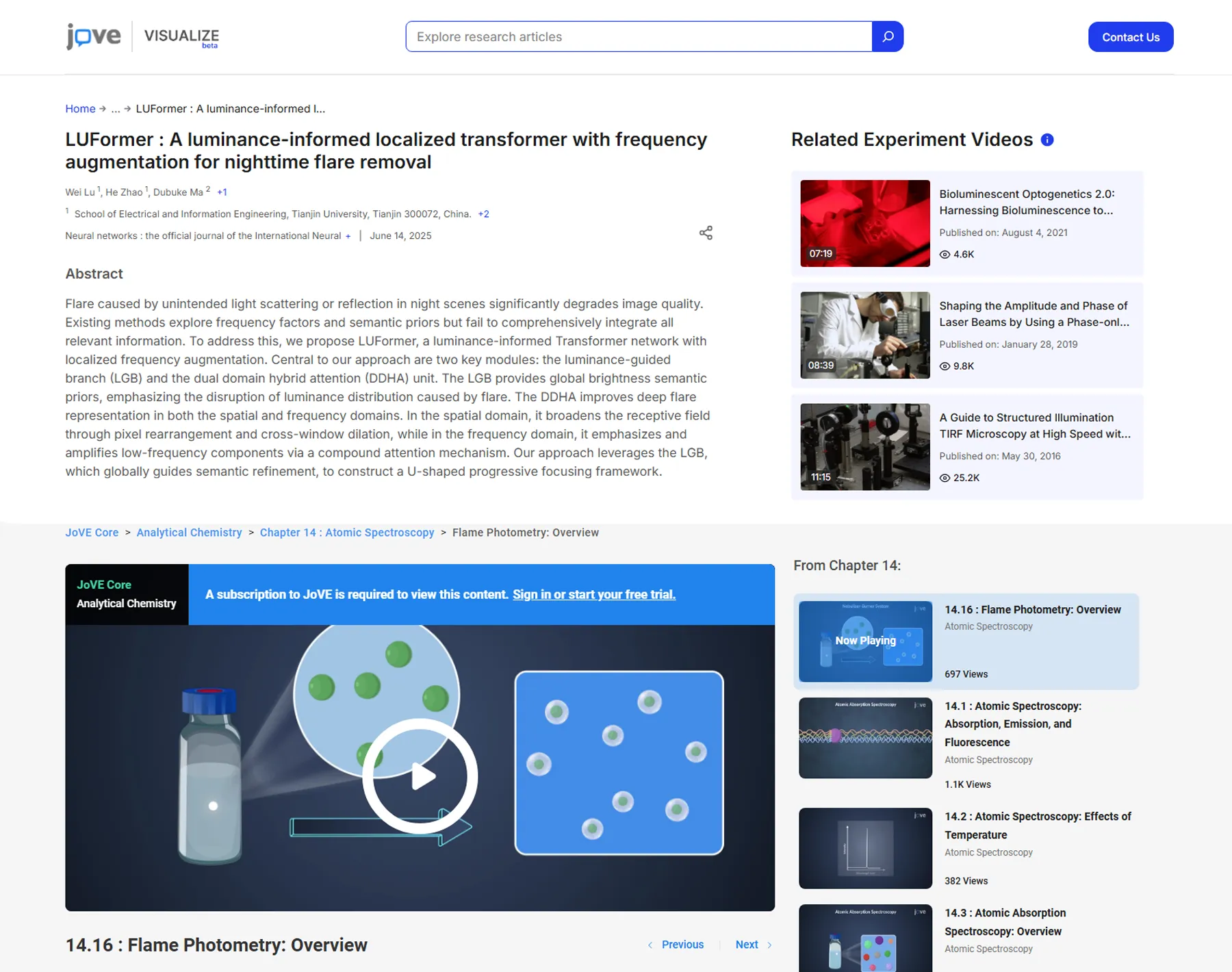
Instead of a complete rebuild, we took an in-depth route. Replacing the failing components, upgrading the architecture, and rebuilding the APIs from the ground up with quick load times were our primary goals.
For starters, we ditched MySQL’s limited search capabilities and replaced it with OpenSearch. This search engine is specifically designed to handle massive datasets and complex queries. Now, researchers can perform deep, lengthy searches across billions of records without watching their browser spin.
Then, for the API layer, we built light, modular REST APIs using Python FastAPI. Each endpoint was optimized for its specific job. This reduced overhead and slashed response times by big numbers. The result was 70% faster performance across the board.
For data ingestion, we rebuilt the entire pipeline. The old cron jobs that kept failing are now part of a completely automated system. So, it reliably processes massive volumes of incoming data without bottlenecks. Data stays fresh, and the system stays responsive.
We containerized everything with Docker, which meant the platform. Additional instances were activated during peak research and went back during quieter (low-search) periods. No more manual scaling or outages during high-demand periods.
Most importantly, the platform is now genuinely useful. Researchers get the instant, deep information they need to understand the impact of their content on the research community.
Project in Figures

5
Month

600+
Estimated Man-hours

3
Team Size
Applied Technologies



More Screens
LOOKING FOR A DESIGN AND DEVELOPMENT PARTNER?